
10 частых проблем парсинга сайтов
Содержание
Интернет является кладезем информации, полезной вашему бизнесу. Он содержит массу идей клиентов, информацию о деятельности конкурентов, их возможностях, успехах и опыте. Это безусловно улучшит ваше положение на рынке. Такие данные нужно обязательно анализировать и быть в курсе дел, поэтому систематизация и анализ данных — неотъемлемая часть успеха бизнеса.
Хитрость заключается в регулярном и быстром получении этих данных. В этом случае парсинг сделает всю «грязную» работу за вас.
Парсинг позволяет получать данные с одного или нескольких источников и хранить их в структурированном, организованном виде. Весь процесс сводится к тому, чтобы создать скрипт для скачивания информации, направить его на целевой сайт и настроить планировщик, который будет регулярно запускать этот скрипт. Написание собственного парсера кажется не сложным. Так ли это?
При использовании собственного парсера существует множество неочевидных подводных камней. Чем ценнее информация, тем сильнее ее защищают от парсинга. Различные методы защиты сильно усложняют разработку и использование парсинга.
Проблемы парсинга
Мы собрали для вас 10 возможных проблем и трудностей, с которыми вы вероятно столкнетесь при работе с парсингом сайтов. Этот список основан на нашем опыте при работе с нашими клиентами.
Воспользуйтесь услугами парсинга от профессионалов и избавьте себя от ряда проблем, описанных ниже.
Слишком быстрое сканирование
При использовании парсинга неизбежно повышение активности целевого сайта. Парсинг страниц имитирует поведение обычного посетителя в том смысле, что каждый запрос заставляет конечный сервер отдавать страницу вместе с любыми вложениями, такими как изображения, скрипты, динамический контент.
Однако, плохо продуманные парсеры открывают страницы гораздо быстрее, чем это делает обычный посетитель. Если позволить скрипту работать слишком быстро, то он создаст сильную нагрузку на веб-сервер и «положит сайт». Эта проблема еще называется DoS-атакой или «отказ в обслуживании». Таким образом вам, как и другим посетителям сайт станет недоступен.

Ошибка 503 Service not available
Опытные владельцы сайтов отслеживают трафик и следят за работоспособностью. При возникновении подобных проблем, настраивается специальное программное обеспечение, которое распознает скриптов-роботов и применяет различные меры защиты.
Попадание в ловушку
Изобретательные разработчики расставляют специальные ловушки в виде ссылок-приманок. Для обычных пользователей эти ссылки не отображаются, но, в то же время, они доступны для парсеров. При переходе по ним сразу становится ясно, что страница открывается нестандартным способом и это является сигналом для применения механизмов защиты.
Конечно, эти ссылки можно обнаружить. Например, они могут содержать теги nofollow, иметь цвет текста, аналогичный цвету фона или просто быть скрытыми с помощью css-стилей. Процесс обнаружения таких ссылок является нетривиальным и часто затратный по времени.
Игнорирование правил robots.txt
Владельцы большинства сайтов электронной коммерции и других ресурсов с интенсивным трафиком понимают, что парсинг вполне имеет место быть. Для формирования поисковой выдачи, поисковые системы тоже используют технологии парсинга. Так что большинство сайтов по-умолчанию дают свое согласие на извлечение данных.
Стандартным методом взаимодействия с роботами поисковых систем является использование файла robots.txt. Этот файл располагается в корневой директории сайта и предназначен для определения правил, которым должен следовать поисковой парсер. К таким правилам относятся частота запросов и запрет или разрешение на доступ к страницам.

Файл robots.txt
Более сложные настройки robots.txt поддерживают расширенные правила, прописанные для каждого отдельного робота. Например, можно разрешить доступ к страницам для поискового робота Google и Яндекс, но в то же время установить запрет на парсеры от различных сервисов или конкурентов.
Таким образом, чтобы парсинг не вызывал подозрений у владельцев сайта, следует придерживаться правил robots.txt и настраивать параметры «на лету».
Многократное сканирование похожими методами
Поскольку, обычному человеку не свойственно выполнять повторяющиеся действия на сайте, нужно избегать парсинга страниц одним и тем же способом. Это еще одна проблема получения данных. Хорошо настроенное защитное программное обеспечение легко обнаружит закономерности просмотра страниц и сообщит администратору об этом.
Чтобы решить эту проблему, нужно имитировать случайные действия человека, например движение курсора мыши, прокрутку, клики в разных местах страницы, произвольные задержки просмотра. Такие действия запутают программное обеспечение мониторинга и позволят избавиться от блокировок парсера.
Повторяющийся User Agent
По умолчанию браузеры также включают заголовок User Agent (пользовательский агент) в каждом запросе к веб-серверу. Подобно описанной выше проблеме с IP-адресом, программное обеспечение мониторинга может легко определять повторяющиеся запросы парсинга, просматривая заголовки повторяющихся User Agent.
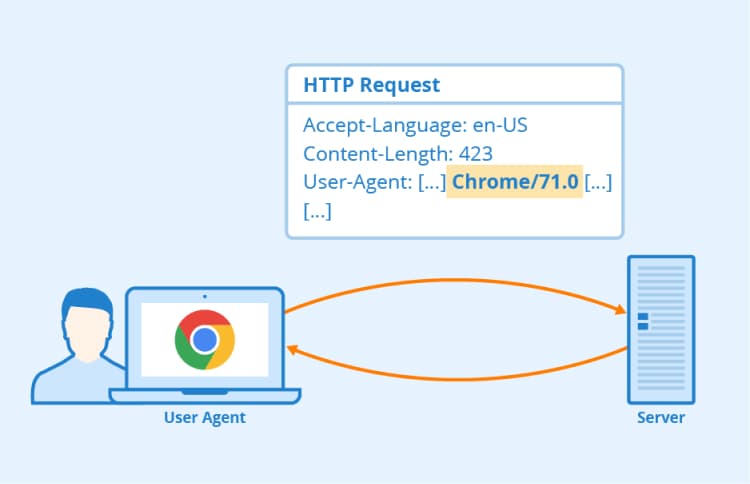
User Agent браузера
Для решения этой проблемы можно использовать такой же подход, как и описанная выше ротация IP. Достаточно устанавливать при парсинге разные заголовки User Agent реальных браузеров или поддельные, похожие на реальные.
Проблема решается разработкой парсера, который перед каждым запросом в веб-серверу брал бы произвольный User Agent из большого списка и использовал его в качестве заголовка.
Игнорирование Cookie
Иногда, при парсинге следует собирать и хранить cookie. Это неочевидно изначально, однако пренебрежение куками, как правило, сильно усложняет процесс парсинга. Например, самые популярные доски объявлений и лидеры рынка электронной коммерции используют cookie для идентификации человеческого фактора и легко определяют, запрашивает ли страницу человек или парсер. Безусловно, для парсера будут применяться различные технологии защиты.
С другой стороны cookie могут принести отрицательный эффект. Например, результаты парсинга поисковых систем Google и Яндекс будут сильно искажены использованием cookie, так как результаты поисковой выдачи персонализируются. Если вы не против получать независимые данные, то работа с cookie будет хорошей практикой.
Парсинг без прокси-серверов
Все запросы к сайту обязательно содержат IP-адрес. Неважно, обычный это человек или поисковая машина, веб-сервер будет знать, с какого IP-адреса поступает запрос.
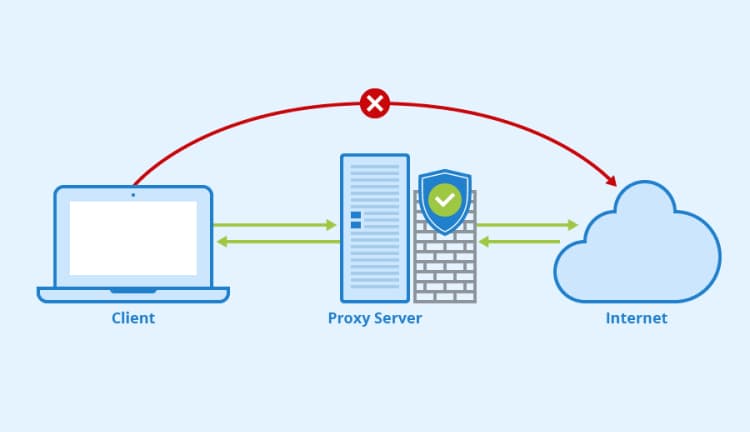
Прокси-сервер
Большинство программного обеспечения идентифицирует парсеры по нескольким запросам с одного и того же IP-адреса. Таким образом, использование разных IP-адресов при парсинге решает эту проблему. Для этого существует такой метод, как ротация IP-адреса. На каждое обращение к сайту, скрипт случайным образом выбирает IP-адрес из целого набора и использует его.
Кроме того, полезно для более сложного парсинга задействовать прокси-серверы (отдельные серверы-шлюзы в интернет) для использования разных IP-адресов в исходящих запросах.
Недооценивание сложности парсинга
Эффективный парсинг сайтов требует хороших знаний в области программирования и веб-технологий, сильных навыков разработки и тестирования программного обеспечения, значительных ресурсов сервера и сети, для выполнения парсинга и поддержки его инфраструктуры.
Кроме этого, нужно уметь управлять несколькими парсерами для работы с множеством источников. Разработка, координация и управление всеми парсерами одновременно быстро выйдет из под контроля при недостаточном внимании. Если парсеры не обслуживаются должным образом, то их работоспособность со временем снижается в связи с изменением целевых доноров.
Наконец, парсинг сайтов сильно усложняется, когда данные поступают из нескольких источников одновременно и собираются в единый файл. Десять разных сайтов могут хранить информацию одного и того же товара десятью разными способами. Все эти необработанные данные необходимо скачивать, анализировать, обрабатывать и согласовывать с вашей моделью данных. Поэтому процесс парсинга может быть не таким простым, как кажется.
Попадание в черный список или бан
Еще одно последствие того, что ваш плохо написанный парсер будет обнаружен, заключается в том, что владелец сайта научится распознавать ваш парсер и запретит ему выполнять те или иные действия. Это может быть как ограничение на доступ к определенному контенту, так и ко всему сайту.

Ошибка 403 Forbidden Error
Если скрипт был успешно запущен и работал, но через какое-то время начали возникать ошибки, значит владелец сайта применил механизмы защиты от парсинга. Такие ошибки часто сопровождаются кодами 40x, но, помимо ошибок, иногда появляются страницы с проверкой captcha или необычные задержки при парсинге.
Очевидно, это мешает получать данные и вам придется скорректировать парсер так, чтобы можно было использовать более продуманную логику в обход блокировок. И такие ситуации будут возникать постоянно, пока вы не сделаете настолько виртуозный парсер, который не будет поддаваться распознаванию со стороны сайта-донора.
Подмена данных
Неосторожный парсинг может вызвать еще большие проблемы, чем запрет или внесение в черный список — подмена данных. Умелые разработчики могут позволить парсеру собирать данные с их сайта, только не тех, которые ожидаются изначально. Без источника для сравнения, парсинг без предупреждения отправит искаженную информацию в базу данных и нарушит весь бизнес-анализ.
Очевидно, что такое положение дел самое негативное и имеет катастрофические последствия для принимающей компании. Поэтому, при разработке парсера, необходимо быть очень осторожным и внимательным и придерживаться вышеупомянутых передовых методов парсинга.
Заключение
Парсинг — это палка о двух концах. С одной стороны он даст любому бизнесу своевременную информацию, которая потенциально увеличит конкурентное преимущество. С другой стороны, это слишком сложно и рискованно, чем кажется на первый взгляд. Существует множество непредвиденных случаев, которые сделают парсинг невозможным и неэффективным.
Компании, которые занимают строго определенную нишу на рынке и имеют хорошую, компетентную техническую поддержку, имеют возможность полноценно заниматься парсингом. Но большинству компаний лучше заказать профессиональные услуги парсинга сайтов. Так вы сможете получить все преимущества получения данных и избежать рисков.

2018 © Парсик
Все права защищены